YesNoError (YNE) Whitepaper v1.0
Abstract
Worldwide, more than 90 million scientific papers have been published, forming the bedrock of modern innovation. Yet despite peer-review safeguards, errors, oversights, and even instances of fraud can remain undetected for years—skewing subsequent research, influencing public policy, and eroding trust in science. YesNoError (YNE) is a decentralized initiative that harnesses advanced Large Language Models (LLMs) to systematically audit this massive corpus of literature. Our short-term aim is to scan and evaluate both legacy and newly published papers for mistakes ranging from simple arithmetic slips to intentional data falsification. Beyond error detection, YNE aspires to become a universal “literature audit” tool, offering researchers, institutions, and the public an accessible way to verify scientific claims. This product roadmap includes a quality ranking system that flags methodological rigor, replicability, and alignment with established data standards—ultimately exposing potential fraud before it can take root. By combining scalable AI audits with decentralized participation, YNE strives to safeguard scientific integrity on a global scale.
1. Introduction
Peer review is fundamental to scientific credibility, yet no human-based system is entirely exempt from error. Throughout history, even high-profile and ostensibly rigorous studies have contained mistakes with serious consequences:
- 2010 Reinhart-Rogoff Paper on Debt and Growth
A coding error in this influential economics paper led to widespread policy debates and austerity measures that may have been based on flawed data. - 1993–1998 Higgs Boson Prediction
Early analyses of particle collider data included computational inaccuracies that muddied the theoretical understanding of the Higgs field prior to its eventual confirmation at CERN. - 2005 Amgen Study on RANKL and Bone Cancer
Methodological oversights led to misinterpretation of RANKL's role in tumor formation, affecting subsequent research directions and clinical trials. - 2000s Gene Therapy Study by Avigen
Oversights in study design and data analysis led to inflated efficacy claims and contributed to a decline in investor and public confidence in gene therapy research.
Common Scientific Pitfalls
In addition to high-profile examples like these, many everyday research mistakes fall into three broad categories: Methodological Errors, Statistical/Analytical Errors, and Interpretational Errors. Understanding these categories helps clarify how studies can go wrong:
- Methodological Errors
- Selection Bias
Occurs when the participants or data are not representative of the target population.
Example: A medical study recruiting only from a single hospital in a wealthy suburb might overrepresent healthier, higher-income individuals. - Sampling Errors & Underpowered Studies
Studies with too few participants often fail to detect true effects or yield wide confidence intervals.
Example: A pilot study with just a handful of subjects may incorrectly conclude a treatment has no effect when it simply lacked statistical power. - Poor Controls or No Control Group
If control groups aren't used or are poorly matched, it's difficult to attribute outcomes to the intervention.
Example: Testing a new drug without comparing it to a placebo or standard treatment introduces confounding factors.
- Selection Bias
- Statistical/Analytical Errors
- Misinterpreting Statistical Significance vs. Practical Significance
Finding a statistically significant result does not always mean it has real-world importance.
Example: A large dataset might reveal a "significant" difference of 0.5 mmHg in blood pressure—clinically trivial. - P-Hacking (Data Dredging)
Repeatedly analyzing data or selectively reporting results to find a "significant" p-value.
Example: Testing dozens of hypotheses until one is significant, then presenting only that one. - Ignoring Confounding Variables
Failing to account for other factors that might drive observed effects.
Example: Claiming a vitamin improves cognitive function without measuring participants' baseline health or diet. - Regression to the Mean
Extreme observations tend to be closer to average upon subsequent measurements.
Example: Students who do extremely well on one test often revert to more typical scores later. - Overfitting Models
Fitting a statistical or machine learning model too closely to training data, capturing noise rather than real patterns.
Example: A highly complex model that explains every data point in a small sample but fails to predict new data.
- Misinterpreting Statistical Significance vs. Practical Significance
- Interpretational Errors
- Post Hoc Ergo Propter Hoc (False Cause)
Assuming that because Event B followed Event A, A caused B.
Example: "I wore a new shirt, then my team won—so the shirt caused the victory." - Confirmation Bias
Seeking or interpreting data that supports pre-existing beliefs, while disregarding contrary evidence.
Example: Only citing studies that show a drug works, ignoring contradictory trials. - Cherry-Picking or Selective Reporting
Highlighting favorable results and omitting negative or null findings.
Example: Publishing only clinical trials with positive outcomes while leaving out those that show no effect. - Overgeneralization
Drawing broad conclusions from narrow data.
Example: Conducting a study with only young, healthy male participants, then applying the results to all demographics.
- Post Hoc Ergo Propter Hoc (False Cause)
Collectively, these pitfalls illustrate how errors can arise at multiple stages—from study design to data analysis and final interpretation. Distinguishing between methodological, statistical, and interpretational issues helps researchers and reviewers pinpoint where a study might have gone astray and what safeguards can be put in place to mitigate such problems.
Recent High-Profile Example
More recently, in 2024, a study in the journal Chemosphere—titled "From e-waste to living space: Flame retardants contaminating household items add to concern about plastic recycling"—reported alarmingly high levels of toxic flame retardants in black plastic household products. Although the initial risk was later deemed overstated, the paper had already triggered significant public anxiety.
When presented to OpenAI's o1 model, the study's central numerical discrepancy was identified in 30 seconds for $0.30, exemplifying AI's potential to detect errors that slip past conventional peer review.
This high-profile "black spatula" incident sparked dialogue among prominent figures in tech and academia, leading to calls for systematic, large-scale AI-driven audits of scientific literature. Steve Newman, creator of Writely (the precursor to Google Docs), proposed an experiment to randomly audit 1,000 published papers via LLMs. Marc Andreessen, a leading venture capitalist, expressed willingness to fund a serious effort at such scale. Ethan Mollick, a Wharton School professor, observed how an LLM identified a math mistake in a short paper that caused widespread alarm—raising the question of whether AI checks should be standard practice in science.
In response, YesNoError (YNE) sets out to extend AI-powered auditing across the entire scientific ecosystem, targeting over 90 million existing research papers and continuously monitoring new publications. However, our vision goes beyond scanning and archiving legacy documents:
- Comprehensive Literature Audit Platform
We plan to develop a user-friendly product that allows anyone—scientists, institutions, journalists, or everyday citizens—to upload and review scientific manuscripts for errors. This feature extends to unpublished research, enabling authors to catch potential pitfalls before formal peer review. - Quality Ranking System
Moving from error detection to insight, YNE will institute a dynamic scoring mechanism that highlights each paper's methodological depth, data transparency, logical coherence, and reproducibility. By providing a tiered ranking, we aim to help users distinguish high-caliber work from studies lacking rigorous foundations. - Fraud Detection and Deterrence
In addition to spotting unintentional errors, YNE's AI workflows will look for patterns indicative of fraudulent activity, such as data reuse, repetitive statistical anomalies, or suspicious publication patterns. By exposing these irregularities early, YNE aims to deter misconduct and preserve public trust in scientific inquiry.
Through its AI-driven audits and open, decentralized approach, YNE seeks to proactively minimize the real-world harm that scientific inaccuracies can inflict. By offering a scalable, transparent framework, we hope to revolutionize how research is validated, ensuring that our collective knowledge is both robust and trustworthy.
2. AI Agent Design
YesNoError's AI auditing platform is built on a multi-layered architecture that ingests, parses, and evaluates scientific manuscripts, ultimately generating a structured report on potential errors and methodological concerns. This section details the technical design, from input parsing and chunk-based analysis to multi-agent orchestration and iterative model improvement.
2.1 Synthetic Data Pipeline

An integral part of YesNoError's approach is the synthetic data pipeline, which supercharges the AI agent's error-detection capabilities by introducing known errors into actual research papers:
- Research Paper Collection
- Manuscripts are aggregated from various sources—arXiv, PubMed, institutional repositories—or uploaded by users.
- Each paper is assigned a unique identifier (paper_id) for tracking and version control.
- Synthetic Error Injection
- A controlled set of fabricated mistakes (e.g., incorrect numerical values, flawed citations, or methodological inconsistencies) is inserted into these papers.
- These injected errors allow the system to measure how well the AI agent can detect known issues.
- AI Error Detection & Scoring
- The YesNoError AI agent attempts to flag the induced errors.
- The system logs the percentage of successfully identified errors to provide an immediate performance metric.
- Iterative Improvements
- Missed errors trigger fine-tuning or prompt-engineering adjustments.
- This cycle repeats, steadily improving detection accuracy against both synthetic and real-world errors.
2.2 Input & Parsing
Document Ingestion
- Manuscripts are uploaded in PDF, Word, or LaTeX format via a web interface or API.
- Each document is assigned a paper_id for traceability.
Text Extraction
- Libraries such as
pdfplumber,PyPDF2, or LaTeX-specific parsers convert the manuscript into raw text. - (Optional) Structural parsing identifies major sections (e.g., Introduction, Methods, Results) by scanning for keywords or LaTeX section headers.
These parsing steps ensure the AI agent receives a clean and properly segmented text input, preparing the data for downstream analysis.
2.3 Chunking & Embedding (RAG Approach)
In many cases, research papers exceed an LLM's token limits, or users may want faster processing. Retrieval-Augmented Generation (RAG) solves this by subdividing documents into smaller "chunks" and embedding them in a vector database:
- Chunking
- Text is split into segments (often ~1,000 tokens each) based on paragraphs, sections, or page boundaries.
- Each chunk is stored with metadata, including page range, section header, and paper_id.
- Vector Embedding & Indexing
- Each chunk is embedded using models such as Sentence-BERT or OpenAI's embedding endpoints.
- The resulting embeddings are stored in a vector database (e.g., FAISS, Pinecone, or Milvus) for fast similarity searches.
- Retrieval
- When the AI needs to perform a specific check (e.g., "check for math errors"), it creates an embedded query.
- Relevant chunks are retrieved via similarity search.
- The top N chunks form a context prompt, which is then fed into the LLM for focused analysis.
This approach maximizes accuracy (by including only relevant text) and efficiency (by avoiding the cost of processing an entire document at once).
2.4 Multi-Agent Orchestration
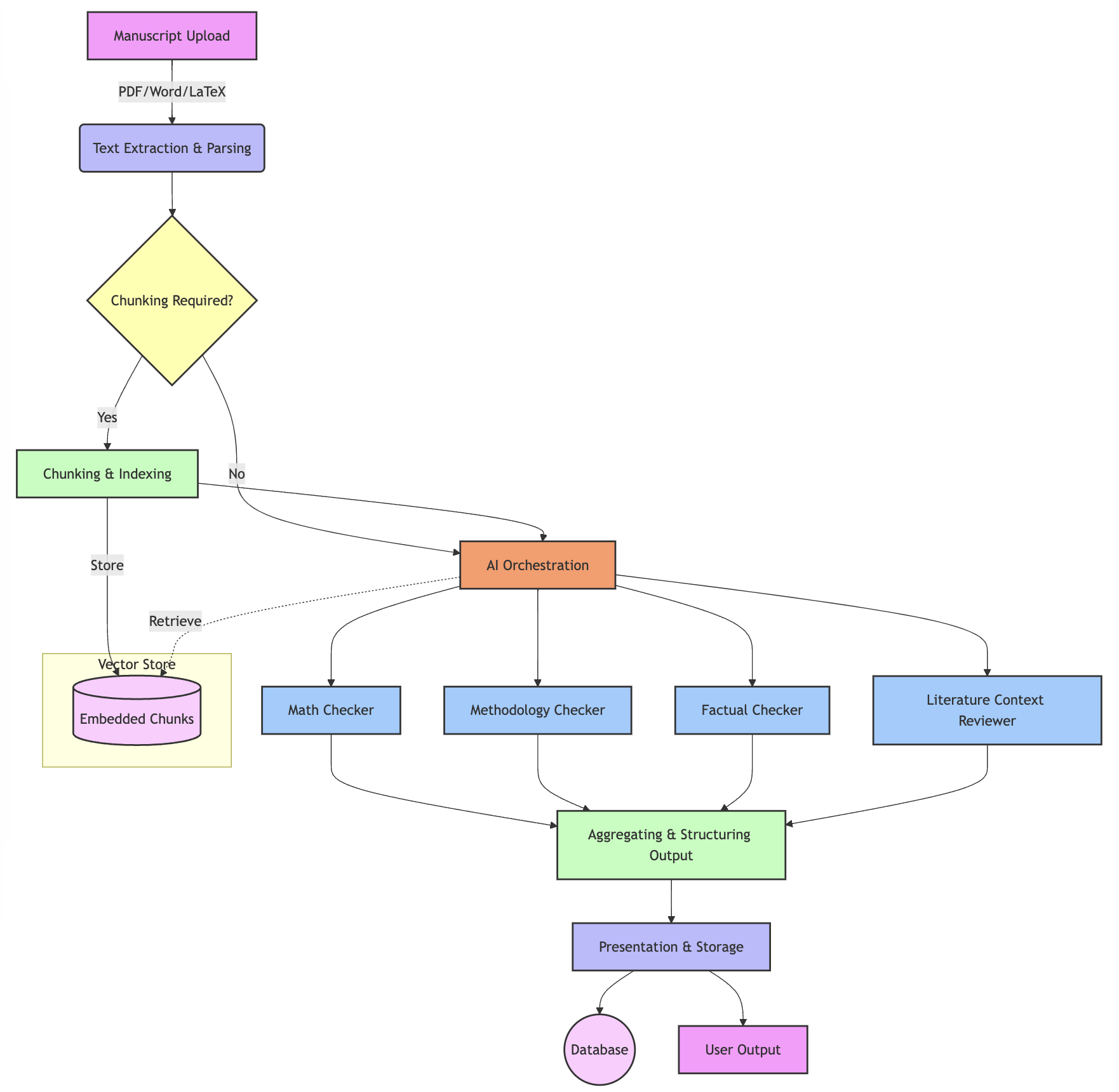
YesNoError's auditing platform uses a multi-agent architecture to distribute tasks among specialized AI reviewers:
- Orchestration Layer
- Coordinates the review of a manuscript (whether via a scheduled process or an ad hoc request).
- Determines which specialized reviewers (agents) will be most relevant—e.g., Math Checker, Methodology Checker, Factual/Reference Checker.
- Specialized AI Reviewers
- Math Checker
Verifies equations, arithmetic operations, bracket mismatches, and the internal consistency of numeric data. - Methodology Checker
Assesses study design, sample sizes, statistical tests used, and reproducibility concerns. - Factual/Reference Checker
Cross-checks references to ensure that cited statements accurately reflect source material. - Logic Checker
Evaluates the internal reasoning for coherence and consistency, flags contradictory statements or unsupported conclusions, and ensures that the argument flow aligns with the stated hypotheses.
- Math Checker
- Communication Flow
- The Orchestration Layer provides each reviewer with relevant text chunks and specific instructions (e.g., "Focus on verifying the formulas in the Methods section").
- Reviewers return structured feedback (e.g., JSON listing identified issues, severity, recommended fixes).
- The Orchestration Layer aggregates and merges these outputs into a consolidated report.
This distribution of tasks to specialized reviewers yields deeper, domain-specific scrutiny and minimizes the chance of one-size-fits-all oversights.
2.5 Output & Structuring
Structured Review Report
- Each manuscript receives a JSON-based report detailing:
- Paper Metadata (title, authors, short summary).
- Identified Errors (categorized by type, severity, and recommended fixes).
- Methodological Assessment (statistical rigor, reproducibility concerns).
- References & Factual Consistency (cross-checked citations).
- Suggested Next Steps (further verification, additional sources, or author clarifications).
Data Persistence
- Reviews are timestamped and linked to the paper_id, maintaining a versioned audit trail of changes and improvements over time.
- This stored data can be revisited and re-audited if the model or prompts are updated.
2.6 Post-Processing & Human Feedback Loop
Verification & Refinement
- Authors or domain experts can confirm or contest flagged errors, creating a collaborative correction process.
- Confirmed findings inform subsequent training iterations, continually honing the AI's detection capabilities.
Continuous Improvement
- The modular design allows new or updated models to be integrated without disrupting the entire pipeline.
- Prompt-engineering strategies (like chunk size or specialized reviewer prompts) are refined based on performance metrics (precision, recall, F1 scores on known error sets).
3. $YNE Token & Utility

While YesNoError's AI architecture addresses the technical challenges of scanning vast research corpora, the question of how to fund and prioritize large-scale audits remains crucial. The $YNE token stands at the intersection of decentralized finance and decentralized science, offering a flexible mechanism for both on-demand reviews and collective focus on specific research domains.
3.1 Community-Driven Prioritization
- Collective Resource Allocation
Beyond individual audits, the $YNE token empowers the community to pool resources and launch large-scale initiatives. For instance, holders can propose a thematic review of long COVID studies or a deep dive into oncology research. - Voting & Campaigns
Community members who own $YNE can vote on which subjects the AI agent should tackle next—ranging from high-profile fields like AI safety or cancer research to under-studied areas lacking sufficient peer review. Once consensus is reached, pooled tokens fund the additional compute resources needed for these extensive audits.
3.2 Incentive Alignment
- Sustaining a Public Good
Large-scale scientific review is often seen as a public good, with no direct profit model. By providing a token-based economy, YesNoError can sustain widespread audits without depending exclusively on traditional grants or institutional budgets.
3.3 Funding Broad-Scale Audits
- Rapid Response
When emerging crises or controversial findings arise (e.g., a new vaccine study or high-stakes AI ethics paper), community stakeholders can rapidly mobilize $YNE to conduct an expedited audit. - Continuous Coverage
Because token holders can continuously direct resources toward areas of collective interest, the system naturally adapts to changing research priorities—ensuring perpetual coverage of hot-topic domains.
3.4 Token Burn Mechanism
In addition to funding audits, YesNoError implements a token burn strategy to support long-term sustainability and value:
- Buyback & Burn: A portion of revenue from AI reviews (and from community-led campaigns) is allocated toward buying back $YNE on the open market and then burning those tokens. This process gradually reduces the total circulating supply, potentially increasing scarcity over time.
- Controlled Burn Thresholds: The platform applies tiered burn targets—for example, burning tokens only above a set treasury surplus or revenue milestone—to keep audits affordable and maintain sufficient liquidity in the market.
- Synergy with Incentives: Balancing a token burn with rewards (for domain experts, validators, or stakers) ensures that both scarcity and ecosystem growth are supported. This approach fosters a healthy economic model wherein active participation is rewarded, even as supply inflation is curbed by periodic burns.
By anchoring the YesNoError platform in a token-powered model, we fuse automated AI auditing with decentralized funding and collective decision-making. Researchers get on-demand access to thorough AI checks, while the broader community can pool efforts to audit entire fields, amplifying the project's impact and reinforcing science's ultimate goal of truth and transparency.
4. Roadmap & Implementation Plan
The following roadmap outlines how YesNoError (YNE) will evolve from its current concept and limited prototypes to a fully operational, large-scale auditing ecosystem. This plan includes phased milestones, technical enhancements, token adoption, partnerships, and risk mitigation strategies to ensure a clear path toward sustained impact.
4.1 Phased Milestones
Phase 1: MVP & Pilot Audits
Scope
- Perform limited-scale AI auditing on a curated set of papers from diverse fields (e.g., medicine, economics, computer science).
- Demonstrate the synthetic data pipeline's effectiveness in injecting and detecting known errors.
Deliverables
- Initial MVP with basic multi-agent orchestration (Math Checker, Methodology Checker, Factual/Reference Checker, Logic Checker).
- Early $YNE utility allowing researchers or institutions to fund pilot audits on specific papers.
- Performance Metrics: Collect baseline data on error detection rates, average cost per audit, and latency.
Phase 2: Token-Integrated Scaling
Scope
- Expand capacity to process 10,000 papers a day.
- Introduce community-driven prioritization, enabling $YNE holders to propose and vote on thematic reviews (e.g., long COVID, AI safety, oncology).
Deliverables
- Full Token Integration: Streamlined workflows for on-demand audit payments and pooled funding for topic-based audits.
- Extended Specialized Agents: Possibly domain-specific checkers (e.g., genetics, clinical trials) if early data shows strong demand.
- Partnerships: Forge pilot programs with selected journals or research consortia to incorporate YNE checks as part of editorial workflows.
- Licensable AI Platform for Researchers: Develop a version of the auditing product to be sold or licensed directly to scientists, labs, and research institutions, allowing them to integrate YesNoError's capabilities into their own review processes.
Phase 3: Full Platform Launch
Scope
- Provide comprehensive coverage of major research repositories (arXiv, PubMed Central, SSRN) and scale multi-agent orchestration for high throughput.
- Launch the Quality Ranking System to evaluate each paper's methodological soundness and reproducibility.
- Integrate Fraud Detection techniques to identify suspect patterns (e.g., data reuse, statistical anomalies).
Deliverables
- Public-Facing "Literature Audit" Dashboard: A user-friendly interface where anyone can track audits, see quality scores, and request reviews.
- Ecosystem Integrations: Formal alignments with scholarly databases and DeSci platforms, making YNE audits easily accessible.
- Performance Milestones: Achieve or surpass targeted metrics (e.g., cost per paper under $1, average error detection rate >80%).
Phase 4: Continuous Innovation & Expansion
Scope
- Maintain perpetual coverage of new publications (e.g., automated scanning of newly uploaded arXiv papers).
- Integrate more advanced LLMs or domain-specialized models to refine detection capabilities further.
Deliverables
- Deeper Community Engagement: Ongoing token-driven proposals for specialized audits and expansions (e.g., underrepresented research areas).
- International Collaborations: Partner with global consortia, regulatory agencies, or philanthropic foundations to fund large-scale, non-commercial audits.
4.2 Technical Milestones
- Enhanced Synthetic Data Pipeline: Increase the complexity and realism of injected errors, adapting to domain-specific nuances (e.g., chemical equations, advanced statistical models).
- Advanced Agent Development: Build out specialized reviewers for high-need areas (e.g., advanced math, genomic data, cryptography).
- Performance Metrics:
- Precision & Recall: Benchmarked across multiple domains to assess detection quality.
- Latency & Cost: Maintain or lower average cost per paper audit while handling larger volumes.
4.3 Ecosystem Partnerships
- Academic Journals & Societies: Encourage editorial boards to leverage YNE audits as a complement to human peer review, increasing confidence in published findings.
- Research Consortia & Labs: Collaborate with large-scale initiatives (e.g., global collaborations on cancer research, AI ethics, or materials science) to regularly audit new papers.
- DeSci Platforms: Integrate with broader decentralized science ecosystems to share data, co-fund audits, and pool knowledge resources.
4.4 Risk Management & Contingency
- Technical Scalability Risks:
- Mitigation: Incremental load-testing, modular expansions of AI orchestration, and caching strategies to handle surges in audit requests.
- Regulatory & Legal Uncertainties:
- Mitigation: Compliance with global data protection standards; optional anonymization or encryption of unpublished manuscripts.
- Token Market Volatility:
- Mitigation: System design that allows flexible pricing in $YNE or stablecoins, ensuring audits remain cost-effective.
- Model Limitations:
- Mitigation: Continual improvement loops with synthetic errors, human feedback, and updated LLMs to reduce hallucinations and biases.
By following this multi-phase roadmap, YesNoError aims to gradually expand its capabilities, ensuring that each step is validated through real-world usage, community feedback, and robust performance metrics. The end goal is a self-sustaining, decentralized ecosystem in which 90+ million research papers—and counting—can be systematically reviewed, leading to deeper trust in scientific findings and more efficient pursuit of knowledge.
5. Conclusion & Future Outlook
YesNoError (YNE) stands at the intersection of artificial intelligence, decentralized science, and community-driven innovation, aiming to tackle one of the most pressing challenges in modern research: ensuring the credibility of scientific literature. From a high-profile error in a 10-page study on black plastic utensils to large-scale oversights in economics, physics, and medical research, the consequences of mistakes—whether unintentional or fraudulent—can ripple through academic fields, public policy, and everyday life.
By deploying advanced LLMs, multi-agent orchestration, and a token-powered incentive system, YNE creates a scalable, transparent framework for auditing both historical and newly published papers. This white paper has outlined:
- Vision & Scope
- A plan to audit the world's 90+ million existing research papers, while continuously monitoring future publications.
- A comprehensive solution for error detection, quality ranking, and fraud deterrence—empowering scientists, institutions, and community members to request or collectively fund reviews.
- Technical Architecture
- Detailed mechanisms for ingesting and parsing manuscripts, chunking and embedding them for Retrieval-Augmented Generation, and orchestrating domain-specific AI reviewers.
- A synthetic data pipeline that injects known errors into papers, improving the AI's detection accuracy through iterative feedback loops.
- $YNE Token Utility
- A dual approach to token usage: on-demand audits for individuals or institutions, plus pooled campaigns for large-scale topic-focused reviews (e.g., oncology, AI safety, climate change).
- Aligning incentives to foster trust, transparency, and sustainable growth of a public good in scientific verification.
- Roadmap & Implementation
- A phased plan that begins with a Minimum Viable Product (MVP), progresses through token-integrated scaling, and culminates in a broad "literature audit" platform with fraud detection and a quality ranking system.
- Clear milestones and performance metrics—cost per paper, detection accuracy, community governance adoption—that gauge ongoing impact and success.
Envisioning Tomorrow
The growing complexity of scientific research, combined with unprecedented publication volumes, calls for novel solutions. YNE offers a blueprint for AI-human collaboration that stands to reshape peer review and knowledge validation. As more LLM improvements emerge and the DeSci ecosystem matures, YNE's architecture can adapt—integrating new specialty checkers, refining chunking and retrieval strategies, and continually training its models on confirmed feedback loops.
Call to Action
Achieving this transformative vision depends on collective participation:
- Researchers & Institutions: Partner with YNE to embed audits into peer-review workflows and preemptively check manuscripts.
- Domain Experts: Provide real-world validation, help refine detection models, and propose specialized checkers for emerging scientific fields.
- Token Holders & Community: Drive the focus of YNE by suggesting topics, funding priority audits, and steering governance to ensure the platform remains a transparent, community-centric resource.
Conclusion
With YesNoError, the research community gains an autonomous ally in maintaining the integrity of scientific literature. By merging cutting-edge AI with a decentralized token framework, YNE delivers a powerful method of surfacing errors, eliminating fraudulent practices, and enhancing the collective credibility of scholarly work. As we expand our coverage, form key collaborations, and refine our detection methods, we invite all stakeholders—scientists, technologists, students, and the broader public—to participate in building a future where research is more accurate, reliable, and ultimately, more impactful than ever before.